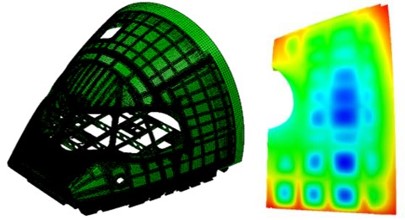
The valley of death in technology development is well-known amongst research engineers and their sponsors. It is the gap between discovery and application, or between realization of an idea in a laboratory and its implementation in the real-world. Some of my research has made it across the valley of death, for example the poleidoscope about 15 years ago (see ‘Poleidoscope (=polariscope+kaleidoscope)‘ on October 14th, 2020). Our work on quantitative comparisons of data fields from physical measurements and computer predictions is about three-quarters of the way across the valley. We published a paper in December (see Dvurecenska et al, 2020) on its application to a large panel from the fuselage of an aircraft based on work we completed as part of the MOTIVATE project. I reported the application of the research in almost real-time in a post in December 2018 (see ‘Industrial Uncertainty‘ on December 12th, 2018) and in further detail in May 2020 as we submitted the manuscript for publication (‘Alleviating industrial uncertainty‘ on May 13th, 2020). However, the realization in the laboratory occurred nearly a decade ago when teams from Michigan State University and the University of Liverpool came together in the ADVISE project funded by EU Framework 7 programme (see Wang et al, 2011). Subsequently, the team at Michigan State University moved to the University of Liverpool and in collaboration with researchers at Empa developed the technique that was applied in the MOTIVATE project (see Sebastian et al 2013). The work published in December represents a step into the valley of death; from a university environment into a full-scale test laboratory at Empa using a real piece of aircraft. The MOTIVATE project involved a further step to a demonstration on an on-going test of a cockpit at Airbus which was also reported in a post last May (see ‘The blind leading the blind‘ on May 27th, 2020). We are now working with Airbus in a new programme to embed the process of quantitative comparison of fields of measurements and predictions into their routine test procedures for aerospace structures. So, I would like to think we are climbing out of the valley.
The valley of death in technology development is well-known amongst research engineers and their sponsors. It is the gap between discovery and application, or between realization of an idea in a laboratory and its implementation in the real-world. Some of my research has made it across the valley of death, for example the poleidoscope about 15 years ago (see ‘Poleidoscope (=polariscope+kaleidoscope)‘ on October 14th, 2020). Our work on quantitative comparisons of data fields from physical measurements and computer predictions is about three-quarters of the way across the valley. We published a paper in December (see Dvurecenska et al, 2020) on its application to a large panel from the fuselage of an aircraft based on work we completed as part of the MOTIVATE project. I reported the application of the research in almost real-time in a post in December 2018 (see ‘Industrial Uncertainty‘ on December 12th, 2018) and in further detail in May 2020 as we submitted the manuscript for publication (‘Alleviating industrial uncertainty‘ on May 13th, 2020). However, the realization in the laboratory occurred nearly a decade ago when teams from Michigan State University and the University of Liverpool came together in the ADVISE project funded by EU Framework 7 programme (see Wang et al, 2011). Subsequently, the team at Michigan State University moved to the University of Liverpool and in collaboration with researchers at Empa developed the technique that was applied in the MOTIVATE project (see Sebastian et al 2013). The work published in December represents a step into the valley of death; from a university environment into a full-scale test laboratory at Empa using a real piece of aircraft. The MOTIVATE project involved a further step to a demonstration on an on-going test of a cockpit at Airbus which was also reported in a post last May (see ‘The blind leading the blind‘ on May 27th, 2020). We are now working with Airbus in a new programme to embed the process of quantitative comparison of fields of measurements and predictions into their routine test procedures for aerospace structures. So, I would like to think we are climbing out of the valley.
Image: not Death Valley but taken on a road trip in 2008 somewhere between Moab, UT and Kanab, UT while living in Okemos, MI.
Sources:
For more posts on the MOTIVATE project: https://realizeengineering.blog/category/myresearch/motivate-project/
 The MOTIVATE project has received funding from the Clean Sky 2 Joint Undertaking under the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 754660 and the Swiss State Secretariat for Education, Research and Innovation under contract number 17.00064.
The MOTIVATE project has received funding from the Clean Sky 2 Joint Undertaking under the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 754660 and the Swiss State Secretariat for Education, Research and Innovation under contract number 17.00064.
The opinions expressed in this blog post reflect only the author’s view and the Clean Sky 2 Joint Undertaking is not responsible for any use that may be made of the information it contains.