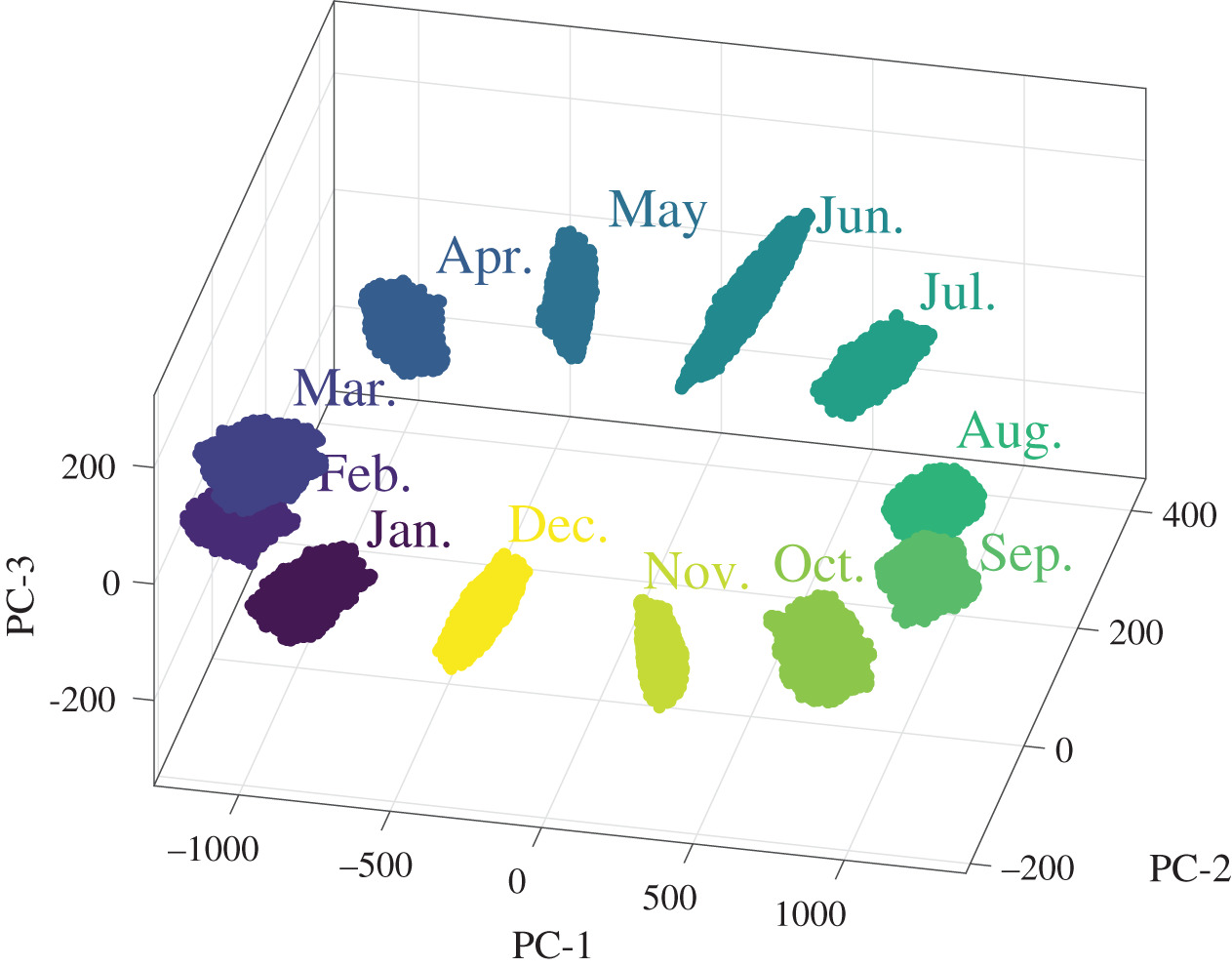
The path from a discovery to a successful innovation is often tortuous and many good ideas fall by the wayside. I have periodically reported on progress along the path for our novel technique for extracting feature vectors from maps of strain data [see ‘Recognizing strain‘ on October 28th, 2015] and its application to validating models of structures by comparing predicted and measured data [see ‘Million to one‘ on November 21st, 2018], and to tracking damage in composite materials [see ‘Spatio-temporal damage maps‘ on May 6th, 2020] as well as in metallic aircraft structures [see ‘Out of the valley of death into a hype cycle‘ on February 24th 2021]. As industrial case studies, we have deployed the technology for validation of predictions of structural behaviour of a prototype aircraft cockpit [see ‘The blind leading the blind‘ on May 27th, 2020] as part of the MOTIVATE project and for damage detection during a wing test as part of the DIMES project. As a result of the experience gained in these case studies, we recently published an enhanced version of our technique for extracting feature vectors that allows us to handle data from irregularly shaped objects or data sets with gaps in them [Christian et al, 2021]. Now, as part of the Smarter Testing project [see ‘Jigsaw puzzling without a picture‘ on October 27th, 2021] and in collaboration with Dassault Systemes, we have developed a web-based widget that implements the enhanced technique for extracting feature vectors and compares datasets from computational models and physical models. The THEON web-based widget is available together with a video demonstration of its use and a user manual. We supplied some exemplar datasets based on our work in structural mechanics as supplementary material associated with our publication; however, it is applicable across a wide range of fields including earth sciences, as we demonstrated in our recent work on El Niño events [see ‘From strain measurements to assessing El Niño events‘ on March 17th, 2021]. We feel that we have taken some significant steps along the innovation path which will lead to adoption of our technique by a wider community; but only time will tell whether this technology survives or falls by the wayside despite our efforts to keep it on track.
The path from a discovery to a successful innovation is often tortuous and many good ideas fall by the wayside. I have periodically reported on progress along the path for our novel technique for extracting feature vectors from maps of strain data [see ‘Recognizing strain‘ on October 28th, 2015] and its application to validating models of structures by comparing predicted and measured data [see ‘Million to one‘ on November 21st, 2018], and to tracking damage in composite materials [see ‘Spatio-temporal damage maps‘ on May 6th, 2020] as well as in metallic aircraft structures [see ‘Out of the valley of death into a hype cycle‘ on February 24th 2021]. As industrial case studies, we have deployed the technology for validation of predictions of structural behaviour of a prototype aircraft cockpit [see ‘The blind leading the blind‘ on May 27th, 2020] as part of the MOTIVATE project and for damage detection during a wing test as part of the DIMES project. As a result of the experience gained in these case studies, we recently published an enhanced version of our technique for extracting feature vectors that allows us to handle data from irregularly shaped objects or data sets with gaps in them [Christian et al, 2021]. Now, as part of the Smarter Testing project [see ‘Jigsaw puzzling without a picture‘ on October 27th, 2021] and in collaboration with Dassault Systemes, we have developed a web-based widget that implements the enhanced technique for extracting feature vectors and compares datasets from computational models and physical models. The THEON web-based widget is available together with a video demonstration of its use and a user manual. We supplied some exemplar datasets based on our work in structural mechanics as supplementary material associated with our publication; however, it is applicable across a wide range of fields including earth sciences, as we demonstrated in our recent work on El Niño events [see ‘From strain measurements to assessing El Niño events‘ on March 17th, 2021]. We feel that we have taken some significant steps along the innovation path which will lead to adoption of our technique by a wider community; but only time will tell whether this technology survives or falls by the wayside despite our efforts to keep it on track.
Bibliography
Christian WJR, Dvurecenska K, Amjad K, Pierce J, Przybyla C & Patterson EA, Real-time quantification of damage in structural materials during mechanical testing, Royal Society Open Science, 7:191407, 2020.
Christian WJ, Dean AD, Dvurecenska K, Middleton CA, Patterson EA. Comparing full-field data from structural components with complicated geometries. Royal Society open science. 8(9):210916, 2021
Dvurecenska K, Graham S, Patelli E & Patterson EA, A probabilistic metric for the validation of computational models, Royal Society Open Science, 5:1180687, 2018.
Middleton CA, Weihrauch M, Christian WJR, Greene RJ & Patterson EA, Detection and tracking of cracks based on thermoelastic stress analysis, R. Soc. Open Sci. 7:200823, 2020.
Wang W, Mottershead JE, Patki A, Patterson EA, Construction of shape features for the representation of full-field displacement/strain data, Applied Mechanics and Materials, 24-25:365-370, 2010.